معرفی و نصب
معرفی هضم¶
هضم کتابخانهای پایتونی برای پردازش زبان فارسی است. با هضم میتوانید متن را نرمالسازی کنید. جملات و واژههای متن را استخراج کنید. ریشهٔ کلمات را پیدا کنید. جملات را تحلیل صرفی و نحوی کنید. وابستگیهای دستوری را در متن شناسایی کنید و ... .
مبتنی بر کتابخانهٔ nltk و سازگار با پایتون +۳.۸
هضم بر مبنای کتابخانهٔ NLTK توسعه داده شده و برای زبان فارسی بومیسازی شده است. هضم با پایتون +۳.۸ سازگار است.
محصولی از تیم روشن
این کتابخانه در ابتدا به عنوان پروژهای شخصی توسعه داده شد و اکنون زیر چتر محصولات روشن در ادامهٔ مسیر توسعه است.
نصب هضم¶
ابتدا پکیج هضم را نصب کنید:
$ pip install hazm
سپس منابع موردنظر را دانلود کنید و ترجیحاً در ریشهٔ پروژه اکسترکت کنید.
و در آخر، هضم را را در پروژه خود ایمپورت کنید:
from hazm import *
استفاده از هضم¶
کد پایین دیدی کلی از کاربردهای هضم نشان میدهد:
>>> from hazm import *
>>> normalizer = Normalizer()
>>> normalizer.normalize('اصلاح نويسه ها و استفاده از نیمفاصله پردازش را آسان مي كند')
'اصلاح نویسهها و استفاده از نیمفاصله پردازش را آسان میکند'
>>> sent_tokenize('ما هم برای وصل کردن آمدیم! ولی برای پردازش، جدا بهتر نیست؟')
['ما هم برای وصل کردن آمدیم!', 'ولی برای پردازش، جدا بهتر نیست؟']
>>> word_tokenize('ولی برای پردازش، جدا بهتر نیست؟')
['ولی', 'برای', 'پردازش', '،', 'جدا', 'بهتر', 'نیست', '؟']
>>> stemmer = Stemmer()
>>> stemmer.stem('کتابها')
'کتاب'
>>> lemmatizer = Lemmatizer()
>>> lemmatizer.lemmatize('میروم')
'رفت#رو'
>>> tagger = POSTagger(model='pos_tagger.model')
>>> tagger.tag(word_tokenize('ما بسیار کتاب میخوانیم'))
[('ما', 'PRO'), ('بسیار', 'ADV'), ('کتاب', 'N'), ('میخوانیم', 'V')]
>>> chunker = Chunker(model='chunker.model')
>>> tagged = tagger.tag(word_tokenize('کتاب خواندن را دوست داریم'))
>>> tree2brackets(chunker.parse(tagged))
'[کتاب خواندن NP] [را POSTP] [دوست داریم VP]'
>>> word_embedding = WordEmbedding(model_type = 'fasttext', model_path = 'word2vec.bin')
>>> word_embedding.doesnt_match(['سلام' ,'درود' ,'خداحافظ' ,'پنجره'])
'پنجره'
>>> word_embedding.doesnt_match(['ساعت' ,'پلنگ' ,'شیر'])
'ساعت'
>>> parser = DependencyParser(tagger=tagger, lemmatizer=lemmatizer)
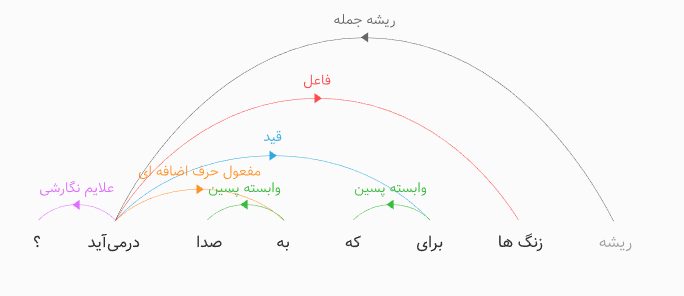
>>> parser.parse(word_tokenize('زنگها برای که به صدا درمیآید؟'))
<DependencyGraph with 8 nodes>
جزئیات بیشترِ این توابع را در بخش کلاسها و توابع پی بگیرید. هضم علاوه بر کلاسها و توابع مختص خود، کلاسها و توابعی نیز برای خواندن پیکرههای مشهور دارد که میتوانید توضیحات هریک از آنها را در بخش پیکرهخوانها بخوانید. هضم مبتنی بر پایتون است؛ با این حال نسخههایی از این کتابخانه به زبانهای دیگر پورت شده است.